
Deep Learning for Object Detection
Deep learning has revolutionized the field of computer vision, specifically the task of object detection. Object detection is the process of identifying and locating objects within an image or video. It has several real-world applications such as surveillance, autonomous vehicles, and robotics. Deep learning algorithms have shown impressive results in object detection tasks, and they have become the go-to approach for developers. This blog post explores the world of deep learning-based object detection algorithms, their significance, and their impact on various domains.
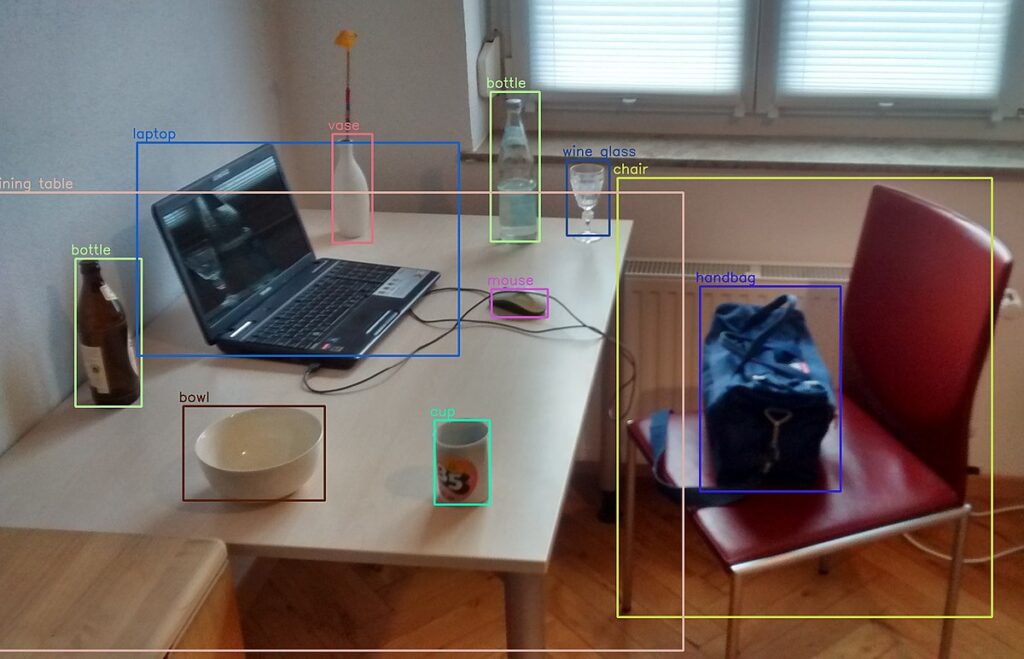
Understanding Object Detection
Object detection refers to the task of identifying and localizing specific objects within an image or video. Unlike image classification, which focuses on assigning a label to an entire image, object detection algorithms precisely locate objects and assign labels to each detected instance. This capability opens doors to a wide range of applications that require detailed object understanding.
Evolution of Object Detection Techniques
Object detection techniques have evolved significantly over the years. Traditional methods relied on handcrafted features and algorithms such as Haar cascades and Histogram of Oriented Gradients (HOG). However, the advent of deep learning has revolutionized the field by leveraging the power of neural networks to automatically learn discriminative features.
Deep learning is a subfield of machine learning that uses artificial neural networks to mimic the human brain’s ability to learn and recognize patterns. With the help of multiple layers of interconnected nodes (neurons), deep learning models can automatically extract hierarchical representations from raw data, enabling more accurate and complex tasks like object detection.
The Role of Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs) lie at the heart of deep learning-based object detection algorithms. CNNs are designed to automatically learn and extract relevant features from images by using convolutional layers, pooling layers, and non-linear activation functions. These features form the basis for detecting objects within images.
Popular Deep Learning Object Detection Algorithms
Several deep learning-based object detection algorithms have gained prominence due to their performance and efficiency. Some notable ones include Single Shot Multibox Detector (SSD), You Only Look Once (YOLO), Region-based Convolutional Neural Networks (R-CNN), and Faster R-CNN. Each algorithm has its unique approach to object detection, combining deep learning principles with innovative techniques.
Single Shot Multibox Detector (SSD)
Single Shot Multibox Detector is a popular deep learning-based object detection algorithm that efficiently detects and localizes objects within images. It was introduced by Liu et al. in 2016, and it has since become widely adopted due to its speed and accuracy.
SSD is a single-pass algorithm that directly predicts object classes and bounding box coordinates in a single network evaluation. It eliminates the need for computationally expensive region proposal generation and subsequent refinement steps, making it significantly faster than its predecessors.
Key Features and Components of SSD:
- Multi-scale feature maps: SSD employs a series of convolutional layers with varying spatial resolutions to extract features at multiple scales. These feature maps capture information at different levels of abstraction, allowing the algorithm to detect objects of different sizes.
- Default anchor boxes: SSD uses anchor boxes, also known as default boxes, to propose potential object locations. These anchor boxes have predefined aspect ratios and scales, which are placed at each spatial location on the feature maps. The algorithm predicts offsets and confidences for these anchor boxes to localize and classify objects.
- Convolutional predictors: At each spatial location on the feature maps, SSD utilizes convolutional layers to predict the class probabilities and offsets for each anchor box. These predictors leverage both global and local contextual information, enabling accurate object detection.
- Multi-scale feature fusion: SSD combines predictions from different layers with varying spatial resolutions to handle objects of different sizes. This fusion allows the algorithm to detect both small and large objects effectively.
- Loss function: SSD employs a combination of classification loss and localization loss to train the network. The classification loss measures the difference between predicted and ground truth object classes, while the localization loss measures the discrepancy between predicted and ground truth bounding box coordinates. These losses are optimized simultaneously to improve detection accuracy.
Advantages of SSD:
- Efficiency: SSD is designed to be fast and efficient. By eliminating the need for separate region proposal stages, it achieves real-time or near real-time performance, making it suitable for applications that require high-speed object detection.
- Accuracy: SSD achieves competitive accuracy compared to other object detection algorithms. Its multi-scale feature maps and default anchor boxes enable accurate detection of objects across various scales and aspect ratios.
- Simplicity: SSD has a relatively straightforward architecture, making it easier to implement and understand. Its simplicity also contributes to its computational efficiency.
Applications of SSD:
SSD has found applications in a wide range of domains, including autonomous driving, video surveillance, object tracking, and augmented reality. Its efficiency and accuracy make it suitable for real-time scenarios where detecting and localizing objects quickly is crucial.
In conclusion, Single Shot Multibox Detector (SSD) is a powerful deep learning-based object detection algorithm that achieves high detection accuracy while maintaining real-time performance. By leveraging multi-scale feature maps, default anchor boxes, and convolutional predictors, SSD offers an efficient and effective solution for object detection tasks in various applications.
You Only Look Once (YOLO)
You Only Look Once is a widely used deep learning-based object detection algorithm that revolutionized real-time object detection. YOLO was introduced by Joseph Redmon et al. in 2016 and has since undergone several iterations, with YOLOv3 being the most popular version.
Key Features and Components of YOLO:
- Single pass detection: YOLO follows a single-pass approach, where a single neural network is employed to predict both bounding box coordinates and class probabilities directly from the input image. This differs from other algorithms that involve multi-stage processes like region proposal and refinement.
- Grid-based prediction: YOLO divides the input image into a grid of cells. Each cell is responsible for predicting bounding boxes and class probabilities for objects that are present within it. This grid-based approach enables YOLO to capture objects of various sizes and aspect ratios across the entire image.
- Anchor boxes: YOLO utilizes anchor boxes to represent different object shapes and sizes. These anchor boxes are pre-defined bounding boxes with specific aspect ratios that are placed at each grid cell. The algorithm predicts offsets and confidences for these anchor boxes to accurately localize and classify objects.
- Convolutional neural network (CNN): YOLO employs a CNN as its backbone network to extract rich features from the input image. This network typically consists of several convolutional layers followed by fully connected layers. The feature maps obtained from the CNN serve as the basis for object detection.
- Multi-scale predictions: YOLO makes predictions at multiple scales by utilizing different layers in the CNN. This enables the algorithm to detect objects of varying sizes, from small to large, effectively.
- Non-maximum suppression (NMS): After making predictions, YOLO utilizes non-maximum suppression to eliminate duplicate detections and select the most confident bounding boxes. NMS helps in reducing redundancy and improving the final detection output.
Advantages of YOLO:
- Real-time performance: YOLO is known for its impressive speed and real-time object detection capabilities. Its single-pass approach eliminates the need for additional time-consuming stages, resulting in faster inference times compared to other algorithms.
- Simplicity and efficiency: YOLO has a relatively simple architecture and is easy to implement. It achieves efficiency by directly predicting bounding boxes and class probabilities, streamlining the detection process.
- Contextual understanding: YOLO benefits from a larger receptive field due to its grid-based approach, allowing it to capture contextual information and dependencies between objects. This aids in accurate object detection and reduces false positives.
Applications of YOLO:
YOLO has been successfully applied to various real-time applications that demand rapid object detection, including video surveillance, autonomous driving, person detection in social media, and robotics. Its efficiency, combined with its ability to handle diverse object sizes, makes it well-suited for these applications.
In conclusion, You Only Look Once (YOLO) is a highly efficient and real-time object detection algorithm. By leveraging a single-pass approach, grid-based predictions, anchor boxes, and a convolutional neural network, YOLO achieves impressive performance in detecting and localizing objects. Its simplicity and speed have made it a popular choice for real-time applications across different domains.
Region-based Convolutional Neural Networks (R-CNN)
Region-based Convolutional Neural Networks is a pioneering deep learning-based object detection algorithm introduced by Ross Girshick et al. in 2014. R-CNN was a significant breakthrough in the field of object detection, laying the foundation for subsequent advancements in this area.
Key Features and Components of R-CNN:
- Region proposal: R-CNN consists of two stages. In the first stage, a selective search algorithm is utilized to generate a set of potential object regions, also known as region proposals. These region proposals aim to identify regions in the image that are likely to contain objects.
- CNN feature extraction: In the second stage, each region proposal is individually fed into a convolutional neural network (CNN) to extract features. The CNN processes the region proposal and generates a fixed-length feature vector that represents the region’s content.
- Region classification: The feature vectors obtained from the CNN are fed into a set of class-specific linear support vector machines (SVMs). These SVMs classify the region proposals into different object categories, such as person, car, or cat. Each SVM is trained to distinguish between a specific object class and background.
- Bounding box regression: R-CNN further refines the localization accuracy of the object proposals by performing bounding box regression. A separate linear regression model is trained to predict the coordinates of the object’s bounding box more accurately, correcting the initial region proposal.
Training Process:
The training process of R-CNN involves several steps:
- Pretraining: The CNN used in R-CNN is typically pretrained on a large-scale dataset, such as ImageNet, to learn general image representations. This pretrained network is then used as a feature extractor for the region proposals.
- Fine-tuning: The CNN layers in R-CNN are fine-tuned using the region proposals and their corresponding ground truth annotations. This step adapts the network to object detection by adjusting the weights to better discriminate between object classes.
- SVM training: The SVM classifiers associated with each object category are trained using the features extracted from the region proposals. Positive samples correspond to region proposals that overlap significantly with ground truth objects, while negative samples are chosen from regions with low overlap.
- Bounding box regression training: Another linear regression model is trained to predict refined bounding box coordinates. The regression targets are calculated based on the ground truth bounding box annotations.
Advantages of R-CNN:
- Accurate localization: R-CNN achieves high localization accuracy by leveraging region proposal algorithms and subsequent refinement steps. The bounding box regression helps improve the precise localization of objects.
- Strong classification performance: By utilizing SVM classifiers, R-CNN achieves robust and discriminative object classification. Each SVM is trained independently for a specific object category, resulting in accurate class predictions.
- Flexibility and extensibility: R-CNN can be extended to incorporate newer and more powerful CNN architectures as feature extractors, allowing for continuous improvements in object detection performance.
Limitations and Improvements:
While R-CNN introduced significant advancements in object detection, it suffers from certain limitations, including slow inference speed due to its multi-stage architecture and high computational requirements during training. Subsequent improvements, such as Fast R-CNN and Faster R-CNN, addressed these limitations by integrating the region proposal generation within the neural network architecture, leading to faster and more efficient object detection.
Applications of R-CNN:
R-CNN and its variants have been successfully applied in various domains, including object detection in images, video surveillance, instance segmentation, and face detection. Its accuracy and robustness make it suitable for scenarios that require detailed object understanding and localization.
Faster R-CNN
Faster R-CNN (Region-based Convolutional Neural Networks) is an advanced deep learning-based object detection algorithm introduced by Shaoqing Ren et al. in 2015. It builds upon the original R-CNN framework and significantly improves the speed and accuracy of object detection.
Key Features and Components of Faster R-CNN:
- Region Proposal Network (RPN): The major innovation in Faster R-CNN is the integration of a Region Proposal Network (RPN) within the neural network architecture. The RPN shares convolutional layers with the subsequent object detection network and generates region proposals directly.
- Anchors: Similar to R-CNN, Faster R-CNN employs anchor boxes as reference bounding boxes with different scales and aspect ratios. The RPN generates region proposals by predicting offsets and confidences for these anchor boxes, effectively proposing potential object locations.
- Region of Interest (RoI) pooling: In Faster R-CNN, a region of interest pooling layer is introduced to extract fixed-length features from the convolutional feature maps generated by the backbone network. The RoI pooling layer allows for efficient processing of region proposals and consistent input sizes for subsequent layers.
- Fast R-CNN for object detection: Faster R-CNN utilizes the Fast R-CNN architecture for object detection, which combines region-wise feature extraction and object classification into a single network. The RoI features obtained from the region proposals are fed into fully connected layers, followed by softmax classifiers for object classification and bounding box regression.
- Training process: The training process of Faster R-CNN involves joint training of the RPN and the Fast R-CNN network. The RPN is trained to generate high-quality region proposals, while the Fast R-CNN network is trained to classify the proposed regions and refine their bounding box coordinates.
Advantages of Faster R-CNN:
- Improved speed: Faster R-CNN achieves faster inference times compared to its predecessor, R-CNN, by integrating the region proposal generation within the neural network architecture. This eliminates the need for separate computation for proposal generation, resulting in significantly faster object detection.
- Accuracy: Faster R-CNN maintains high accuracy in object detection. The integration of the RPN allows for more accurate region proposals, while the Fast R-CNN network effectively classifies and refines the proposals, leading to improved detection performance.
- End-to-end training: Faster R-CNN enables end-to-end training, allowing the network to learn features and object detection simultaneously. This joint training improves the overall performance and ensures optimal feature representations.
- Flexibility: Faster R-CNN is flexible and can be adapted to different object detection tasks by adjusting the network architecture and hyperparameters. It can handle objects of varying scales and aspect ratios efficiently.
Applications of Faster R-CNN:
Faster R-CNN has been successfully applied in a wide range of applications, including object detection in images and videos, instance segmentation, face detection, and pedestrian detection. Its combination of speed and accuracy makes it suitable for real-time and high-performance object detection tasks.
In conclusion, Faster R-CNN revolutionized the field of object detection by introducing the Region Proposal Network (RPN) and integrating it within the neural network architecture. By combining efficient region proposal generation, RoI pooling, and Fast R-CNN for object detection, Faster R-CNN achieves significant improvements in speed and accuracy, making it a widely adopted algorithm for various object detection applications.
Key Components of Deep Learning Object Detection Algorithms
Deep learning object detection algorithms consist of several key components working together to achieve accurate results. These components include input preprocessing, feature extraction, region proposal networks (RPN), and classification and localization mechanisms. Each step contributes to the overall detection process and ensures precise object identification.
Training Deep Learning Object Detection Models
Training deep learning object detection models involves feeding labeled training data into the algorithm and iteratively updating the model’s parameters to minimize the difference between predicted and ground truth object annotations. This process, known as supervised learning, requires a large dataset with annotated images, where each object instance is labeled with its corresponding class and bounding box coordinates.
During training, the deep learning algorithm learns to recognize patterns and features that are characteristic of different objects. The algorithm adjusts its internal parameters, optimizing the network’s ability to accurately classify and locate objects in new, unseen images.
To enhance the performance and generalization of the model, techniques like data augmentation and transfer learning are often employed. Data augmentation involves applying random transformations such as rotations, translations, and scaling to artificially increase the diversity of the training data. Transfer learning, on the other hand, involves leveraging pre-trained models that have been trained on large-scale datasets like ImageNet. By utilizing the learned representations from these models, the object detection algorithm can effectively generalize to new datasets with limited labeled examples.
Evaluation Metrics for Object Detection
To evaluate the performance of deep learning object detection algorithms, various metrics are utilized. Two commonly used metrics are precision and recall. Precision measures the proportion of correctly detected objects out of all the objects predicted by the algorithm. Recall, on the other hand, calculates the proportion of correctly detected objects out of all the ground truth objects present in the image. These metrics are often combined using the F1-score, which provides a single measure of the algorithm’s overall performance.
Applications of Deep Learning Object Detection Algorithms
Deep learning-based object detection algorithms have found applications in various domains, transforming how machines perceive and interact with the visual world. Here are some notable applications:
- Autonomous Vehicles: Object detection enables self-driving cars to detect and track pedestrians, vehicles, and traffic signs, enhancing safety and decision-making capabilities.
- Surveillance Systems: Object detection algorithms are used to monitor public spaces, identifying and tracking suspicious activities or individuals in real-time.
- Medical Imaging: Deep learning object detection assists in medical diagnosis by automatically identifying anatomical structures, tumors, or abnormalities in radiological images.
- Robotics and Automation: Object detection algorithms empower robots to perceive and manipulate objects in their environment, enabling tasks such as picking and sorting items in warehouses or assembly lines.
- Augmented Reality (AR): AR applications rely on object detection to accurately place virtual objects in real-world scenes, creating immersive and interactive user experiences.
Future Directions and Challenges
As deep learning object detection algorithms continue to evolve, several challenges and future directions arise. One such challenge is achieving real-time performance on resource-constrained devices. Optimizing algorithms to run efficiently on embedded systems and edge devices is crucial for applications like drones and mobile devices.
Furthermore, improving the robustness and generalization of object detection algorithms in complex and dynamic environments remains a focus. Overcoming issues related to occlusion, viewpoint variations, and small object detection will enhance the reliability and applicability of these algorithms.
Conclusion
Deep learning-based object detection algorithms have revolutionized the field of visual recognition, enabling machines to accurately identify and locate objects in images and videos. By leveraging the power of convolutional neural networks and training on large annotated datasets, these algorithms have found applications in various domains, from autonomous vehicles to medical imaging. Continued research and advancements in this field will pave the way for enhanced object detection capabilities, unlocking new possibilities in automation, safety, and human-machine interaction.
Further Readings
If you’re interested in further exploring the topic of object detection and related algorithms, here are some recommended readings:
- “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks” by Shaoqing Ren et al. (2015): The original paper introducing the Faster R-CNN algorithm. It provides in-depth details about the architecture and training process.
- “Rich feature hierarchies for accurate object detection and semantic segmentation” by Ross Girshick et al. (2014): The paper that introduced the R-CNN algorithm, which laid the foundation for Faster R-CNN. It covers the initial breakthrough in using deep learning for object detection.
- “You Only Look Once: Unified, Real-Time Object Detection” by Joseph Redmon et al. (2016): The paper introducing the YOLO algorithm, another popular real-time object detection approach. It provides insights into the single-pass detection paradigm.
- “Single Shot MultiBox Detector” by Wei Liu et al. (2016): The paper introducing the SSD algorithm, which combines efficiency and accuracy in object detection. It discusses the architecture and trade-offs between speed and performance.
- “Object Detection with Deep Learning: A Review” by A. Majumdar et al. (2020): A comprehensive review paper that covers various deep learning-based object detection algorithms, including R-CNN, Fast R-CNN, Faster R-CNN, YOLO, and SSD. It provides a broader perspective on the topic.
- “Deep Learning for Object Detection: A Comprehensive Review” by R. B. Girgis et al. (2021): Another comprehensive review paper that surveys the latest advancements in deep learning-based object detection. It covers different algorithms, architectures, datasets, and evaluation metrics.
- “Computer Vision: Algorithms and Applications” by Richard Szeliski: A widely recommended book that covers various computer vision topics, including object detection. It offers a comprehensive overview of the underlying concepts, algorithms, and practical applications.
Remember to access these resources through appropriate channels, such as academic databases, official websites, or reputable sources.