
Convolutional Neural Networks (CNNs) have revolutionized the field of computer vision and have become a vital tool for a wide range of applications such as image classification, object detection, and segmentation. CNNs are a type of deep learning model that is inspired by the way the human brain processes visual information.
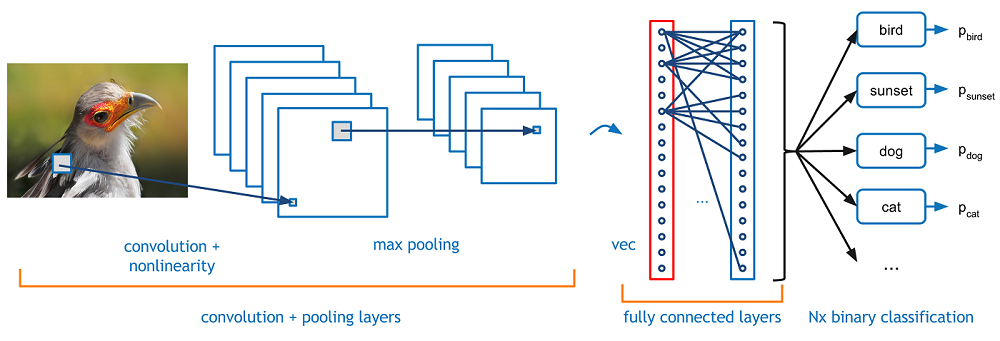
CNNs have a long and interesting history, dating back to the 1980s. However, it wasn’t until the early 2010s when the availability of large amounts of data and powerful GPUs made it possible to train very deep neural networks that CNNs became the state-of-the-art for image processing tasks. Since then, CNNs have been used in a wide range of applications, including self-driving cars, medical imaging, and facial recognition.
The purpose of this article is to provide an overview of CNNs, how they work, and their applications. We will also discuss recent advancements in CNNs, their limitations, and future directions for research and development.
Basic structure of CNNs
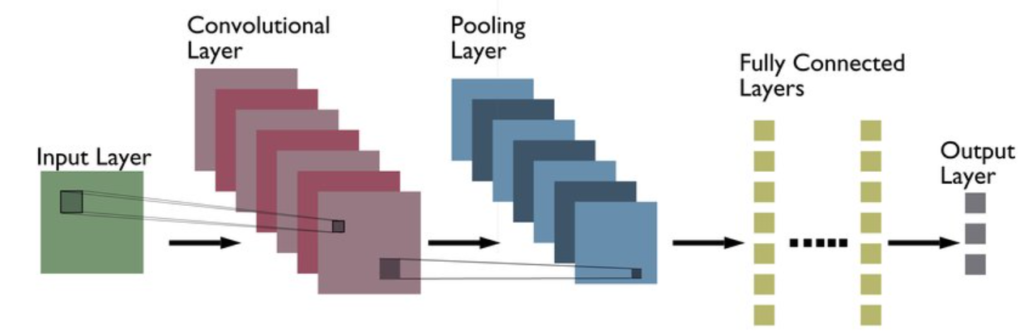
The basic structure of a CNN consists of three types of layers: convolutional layers, pooling layers, and fully connected layers.
Convolutional Layers
Convolutional layers are the key building blocks of a CNN. Each convolutional layer learns a set of filters that convolve with the input data to produce a feature map. The filters are small matrices of weights that are learned during the training process.
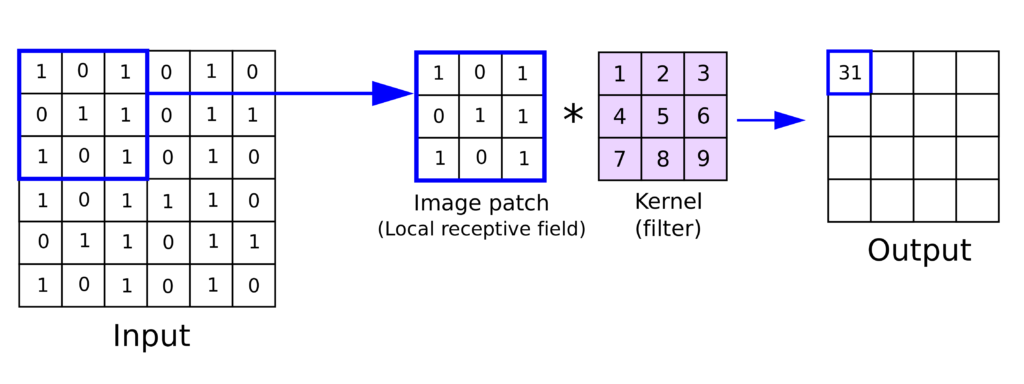
The convolution operation involves sliding the filter over the input data and computing the dot product between the filter and the input data at each location. The result is a single value in the feature map that represents how well the filter matches the input data at that location. The filter is then moved to the next location and the process is repeated until the entire input data has been covered.
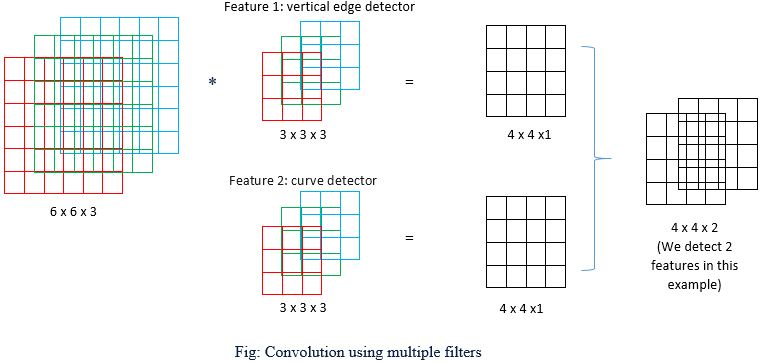
Convolutional layers can have multiple filters, each learning to detect a different feature in the input data. For example, a filter might learn to detect horizontal lines, while another filter learns to detect vertical lines. As a result, convolutional layers can learn to detect complex features such as edges, corners, and other patterns that are relevant to the task at hand.
The size and number of filters in a convolutional layer can be adjusted depending on the complexity of the task. The stride and padding of the convolution operation can also be adjusted to control the size of the output feature map. Stride refers to the number of pixels that the filter is moved during each step of the convolution operation. A stride of 1 means that the filter moves one pixel at a time, while a stride of 2 means that the filter moves two pixels at a time. Increasing the stride reduces the output size of the convolutional layer because fewer convolutions are performed.
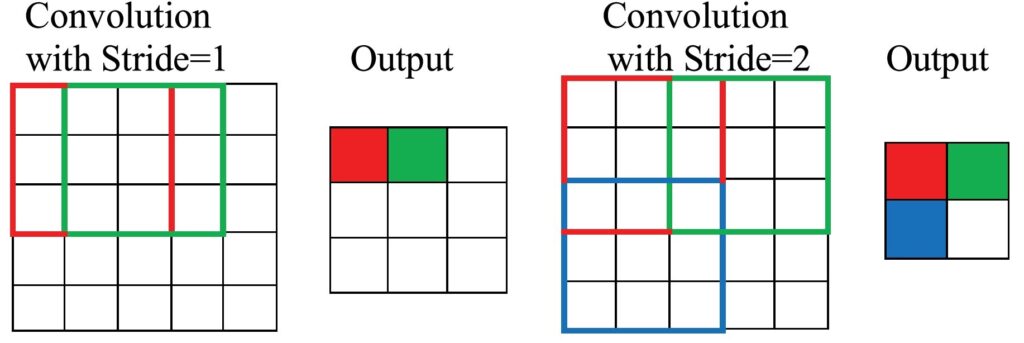
Padding refers to adding additional pixels around the edge of the input image before performing the convolution operation. Padding can be used to control the size of the output of the convolutional layer. There are two types of padding: valid padding and same padding.
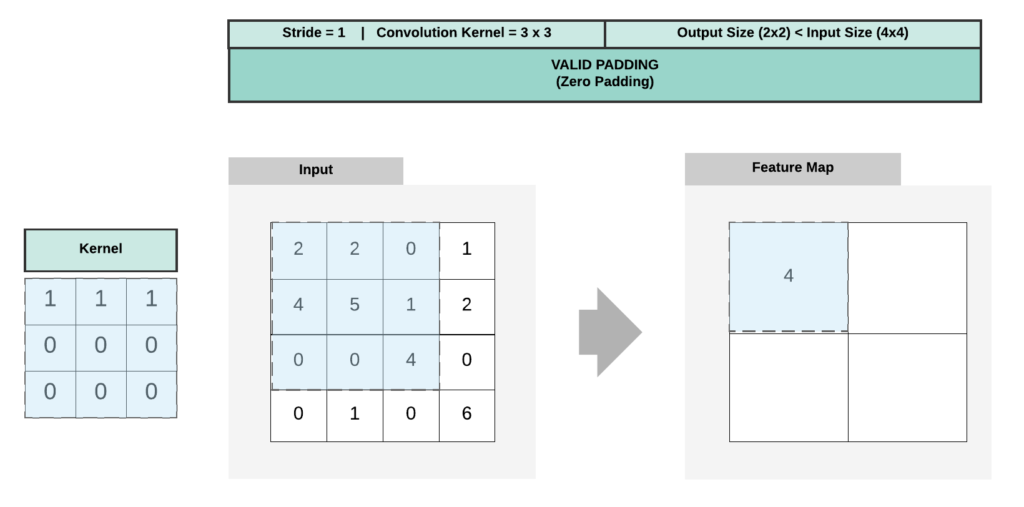
Valid padding means that no padding is added, and the output size of the convolutional layer is reduced by the size of the filter minus one. For example, if the input image is 28×28 and the filter is 3×3, the output size would be 26×26.
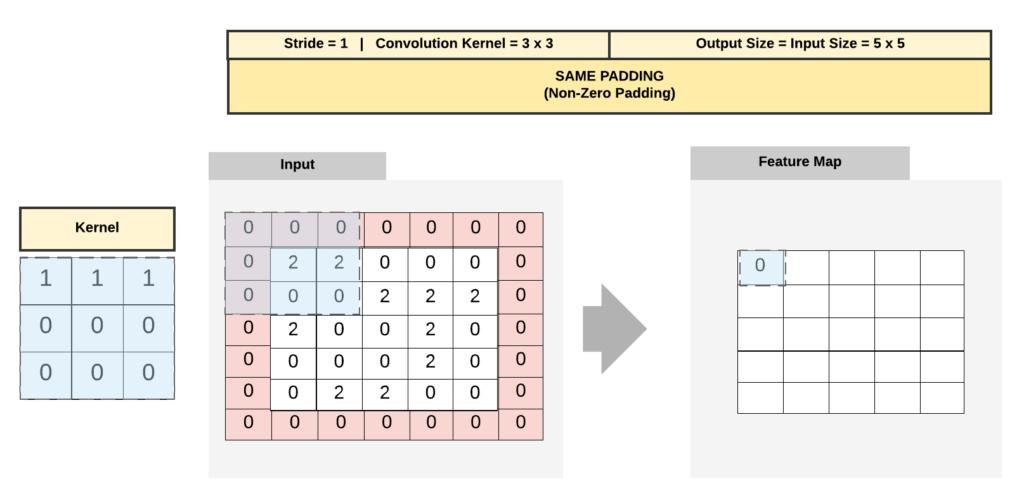
Same padding means that padding is added to the input image so that the output size of the convolutional layer is the same as the input size. To achieve this, padding is added to the input image so that the filter is centered over every pixel in the input image. For example, if the input image is 28×28 and the filter is 3×3, the output size would be 28×28 with padding of one pixel on each side.
Convolutional layers are often followed by activation functions such as ReLU, which introduce non-linearity into the model. This is important because many real-world problems are not linearly separable, and non-linear activation functions are needed to learn complex decision boundaries.
In summary, convolutional layers are the most important building blocks of a CNN. They learn a set of filters that convolve with the input data to produce a feature map. Convolutional layers can learn complex features such as edges, corners, and other patterns that are relevant to the task at hand. The size and number of filters, as well as the stride and padding of the convolution operation, can be adjusted to control the size of the output feature map.
Pooling Layers
Pooling layers are another important building block of a CNN. They are used to reduce the spatial dimension of the feature maps produced by the convolutional layers, making the model more efficient and reducing the risk of overfitting.
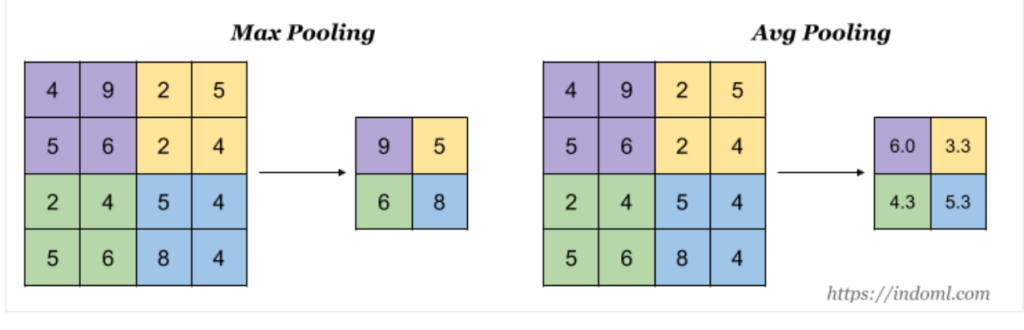
There are several types of pooling operations, but the most common one is max pooling. Max pooling takes the maximum value in a given area of the feature map and uses it as the output value. For example, if we use a 2×2 max pooling operation, the maximum value in each 2×2 block of the feature map is selected and used as the output value. This reduces the size of the feature map by half in each dimension.
Max pooling has several benefits. It reduces the number of parameters in the model, making it more efficient and less prone to overfitting. It also helps the model to be more robust to variations in the input data, such as translations or rotations, because the maximum value is more likely to capture the most important feature in a given area of the feature map.
Another type of pooling operation is average pooling, which takes the average value in a given area of the feature map and uses it as the output value. Average pooling is less common than max pooling because it tends to blur the features in the feature map and make them less distinct.
Pooling layers are typically applied after one or more convolutional layers. The number and size of the pooling layers can be adjusted depending on the task and the available data. A larger pooling operation reduces the size of the feature map more aggressively, but also reduces the amount of information in the feature map. This can be a trade-off between efficiency and accuracy, and the appropriate pooling operation should be selected based on the specific task.
In summary, pooling layers are used to reduce the spatial dimension of the feature maps produced by the convolutional layers. Max pooling is the most common type of pooling operation and reduces the size of the feature map by selecting the maximum value in a given area. Pooling layers help to make the model more efficient and less prone to overfitting.
Activation Functions
Activation functions are an important component of convolutional neural networks (CNNs) because they introduce non-linearity into the model. Non-linearity is necessary because many real-world problems are not linearly separable, and non-linear activation functions are needed to learn complex decision boundaries.
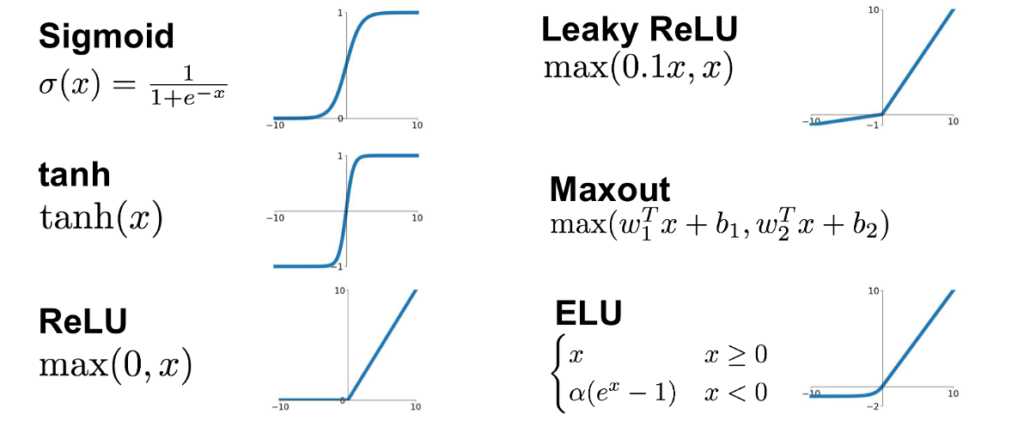
The most commonly used activation function in CNNs is the rectified linear unit (ReLU). ReLU is a simple function that sets any negative input value to zero and leaves any positive input value unchanged. Mathematically, it can be defined as f(x) = max(0, x). ReLU is preferred over other activation functions such as sigmoid and tanh because it is computationally efficient and does not suffer from the vanishing gradient problem.
The vanishing gradient problem occurs when the gradient of the activation function becomes very small as the input becomes very large or very small. This can cause the gradient of the loss function to become very small, making it difficult for the model to learn. ReLU does not suffer from this problem because it has a constant gradient for positive input values.
Other activation functions that are commonly used in CNNs include sigmoid, tanh, and softmax. Sigmoid and tanh are similar to ReLU but have different shapes. Sigmoid squashes the input values between 0 and 1, while tanh squashes the input values between -1 and 1. Softmax is used in the output layer of CNNs to convert the output values to a probability distribution over the output classes.
The choice of activation function can have a significant impact on the performance of a CNN. ReLU is the most commonly used activation function because of its simplicity and efficiency. However, other activation functions may be more appropriate for specific tasks or architectures.
In summary, activation functions are an important component of CNNs because they introduce non-linearity into the model. The most commonly used activation function is ReLU, which sets any negative input value to zero and leaves any positive input value unchanged. Other activation functions include sigmoid, tanh, and softmax. The choice of activation function can have a significant impact on the performance of a CNN.
Fully Connected Layers
Fully connected layers are the final building block of a convolutional neural network (CNN). They are used to map the high-level features learned by the convolutional and pooling layers to the output classes.
A fully connected layer is a traditional neural network layer where each neuron is connected to every neuron in the previous layer. The input to the fully connected layer is a flattened version of the output of the last convolutional and pooling layer. The number of neurons in the fully connected layer is equal to the number of output classes.
During training, the weights of the fully connected layer are adjusted to minimize the loss function. The loss function measures the difference between the predicted output of the model and the true output. The optimizer is used to adjust the weights of the fully connected layer based on the gradient of the loss function.
The output of the fully connected layer is passed through an activation function, usually softmax, which converts the output to a probability distribution over the output classes. The output class with the highest probability is selected as the predicted output of the model.
The number of fully connected layers and their size can be adjusted depending on the complexity of the task. In some cases, multiple fully connected layers are used to increase the representational power of the model. However, more complex models may require more training data and longer training times.
Fully connected layers can also be a source of overfitting, especially if the model is too complex relative to the available training data. Regularization techniques such as dropout can be used to prevent overfitting by randomly dropping out some of the neurons during training.
In summary, fully connected layers are used to map the high-level features learned by the convolutional and pooling layers to the output classes. The output of the fully connected layer is passed through an activation function, usually softmax, to convert it to a probability distribution over the output classes. The number and size of the fully connected layers can be adjusted depending on the complexity of the task. Regularization techniques such as dropout can be used to prevent overfitting.
Training CNNs
Training a convolutional neural network (CNN) involves adjusting the weights of the network to minimize the loss function. The loss function measures the difference between the predicted output of the model and the true output. The weights of the network are adjusted during training using a process called backpropagation.
The training process involves the following steps:
- Data Preparation: The first step is to prepare the training data. The data is typically split into training, validation, and test sets. The training set is used to adjust the weights of the network, while the validation set is used to tune the hyperparameters of the model, such as the learning rate and regularization strength. The test set is used to evaluate the performance of the model on unseen data.
- Forward Propagation: During the forward propagation phase, the input data is passed through the layers of the network, and the output is calculated. Each layer applies a transformation to the input data using the learned weights and activation function.
- Loss Calculation: The loss function is then calculated based on the difference between the predicted output of the model and the true output. The goal of training is to minimize the loss function.
- Backpropagation: The backpropagation algorithm is used to calculate the gradient of the loss function with respect to each weight in the network. This gradient is then used to update the weights of the network to minimize the loss function.
- Parameter Updates: The weights of the network are updated using an optimization algorithm such as stochastic gradient descent (SGD) or Adam. These algorithms adjust the weights in the direction of the negative gradient of the loss function.
- Repeat: The forward propagation, loss calculation, backpropagation, and parameter update steps are repeated for a fixed number of iterations or until the loss function reaches a desired threshold.
During training, several hyperparameters can be adjusted, such as the learning rate, batch size, and regularization strength. The learning rate controls the step size of the optimization algorithm and can have a significant impact on the performance of the model. The batch size controls the number of samples that are processed in each iteration of the training process. A larger batch size can lead to faster convergence, but may also require more memory. Regularization techniques such as dropout or L2 regularization can be used to prevent overfitting.
In summary, training a CNN involves adjusting the weights of the network to minimize the loss function using backpropagation and an optimization algorithm. Several hyperparameters can be adjusted during training, such as the learning rate, batch size, and regularization strength. The training process typically involves splitting the data into training, validation, and test sets.
Applications of CNNs
Convolutional neural networks (CNNs) have numerous applications in computer vision and image processing. Here are some of the most common applications of CNNs:
- Image Classification: CNNs are widely used for image classification tasks, where the goal is to assign a label to an input image. Examples of image classification tasks include identifying objects in an image or distinguishing between different types of images, such as faces or landscapes.
- Object Detection: Object detection involves identifying the location and type of objects in an image or video. CNNs can be used for object detection by first generating a set of proposals or regions of interest in the image and then classifying each proposal as an object or background.
- Image Segmentation: Image segmentation involves partitioning an image into different regions or segments based on their similarity. CNNs can be used for image segmentation by learning to assign each pixel in the image to a specific segment or class.
- Facial Recognition: CNNs are widely used for facial recognition tasks, such as identifying individuals in images or videos. CNNs can learn to extract features that are invariant to variations in lighting, pose, and expression, making them well-suited for facial recognition tasks.
- Medical Imaging: CNNs are increasingly being used for medical imaging tasks, such as identifying tumors in CT scans or diagnosing diseases based on MRI images. CNNs can learn to extract features that are relevant to the diagnosis or classification task, making them well-suited for medical imaging applications.
Other applications of CNNs include natural language processing, autonomous vehicles, and robotics. CNNs have also been used for artistic applications, such as style transfer and image synthesis.
In summary, convolutional neural networks have numerous applications in computer vision and image processing. They are widely used for image classification, object detection, image segmentation, facial recognition, medical imaging, and many other applications. CNNs have also been used for artistic applications and have potential applications in other fields such as natural language processing, autonomous vehicles, and robotics.
Recent Advancements in CNNs
Convolutional neural networks (CNNs) have seen numerous advancements in recent years, driven by advancements in hardware, software, and algorithms. Here are some of the most notable recent advancements in CNNs:
- Transfer Learning: Transfer learning is a technique where a pre-trained CNN is used as a starting point for a new task. By starting with a pre-trained CNN, it is possible to train a new model on a smaller dataset or with less compute resources. Transfer learning has been used in a wide range of applications, from image classification to natural language processing.
- Generative Adversarial Networks (GANs): GANs are a type of neural network that can generate realistic images or other data based on a given set of input parameters. GANs consist of two networks: a generator network that generates the data, and a discriminator network that distinguishes between real and fake data. GANs have been used for applications such as image synthesis, data augmentation, and video prediction.
- Attention Mechanisms: Attention mechanisms are a technique where a CNN learns to selectively focus on certain parts of an image or sequence of data. Attention mechanisms have been used in natural language processing and image classification tasks, where they can improve the accuracy and efficiency of the model.
- Capsule Networks: Capsule networks are a type of neural network that are designed to better capture the hierarchical structure of visual data. Capsule networks use capsules, which are groups of neurons that represent an instance of an object or a part of an object. Capsule networks have shown promising results in image classification and object recognition tasks.
- Efficient CNNs: Efficient CNNs are a type of neural network that are designed to be more efficient in terms of memory usage and computation time. Efficient CNNs achieve this by using techniques such as depthwise separable convolutions and channel pruning. Efficient CNNs have been used in mobile devices and other resource-constrained environments.
In summary, recent advancements in CNNs have included transfer learning, GANs, attention mechanisms, capsule networks, and efficient CNNs. These advancements have led to improved performance, efficiency, and flexibility in CNNs and have opened up new applications in fields such as natural language processing, robotics, and healthcare.
Challenges and Limitations of CNNs
Despite their many successes, convolutional neural networks (CNNs) also face several challenges and limitations. Here are some of the most notable challenges and limitations of CNNs:
- Data Bias: CNNs are prone to bias if the training data is not representative of the population or if there is bias in the labeling of the data. This can lead to incorrect predictions and reduced accuracy in real-world applications.
- Overfitting: CNNs can also overfit the training data if they are too complex relative to the available data. Overfitting can lead to reduced generalization performance and poor performance on new, unseen data.
- Limited Interpretability: CNNs are often considered black boxes because they can be difficult to interpret. It can be difficult to understand why a CNN made a certain prediction, or which features in the input data were most important for the prediction.
- Computational Requirements: CNNs can be computationally intensive, requiring large amounts of memory and processing power. This can limit their use in resource-constrained environments such as mobile devices or embedded systems.
- Lack of Context: CNNs are designed to operate on individual images or video frames, and do not take into account the temporal or contextual information of the data. This can limit their ability to perform tasks such as video analysis or natural language processing.
- Limited Robustness: CNNs can also be sensitive to variations in the input data, such as changes in lighting, viewpoint, or noise. This can limit their robustness and performance in real-world applications.
- Limited Adaptability: CNNs are designed for specific tasks, and can be difficult to adapt to new tasks or data. This can limit their flexibility and applicability in real-world scenarios.
In summary, convolutional neural networks (CNNs) face several challenges and limitations, including data bias, overfitting, limited interpretability, computational requirements, lack of context, limited robustness, and limited adaptability. Addressing these challenges will require ongoing research and development in the field of deep learning.
Future directions for CNNs
Convolutional neural networks (CNNs) have seen significant advancements in recent years, but there are still several areas for future research and development. Here are some of the most promising future directions for CNNs:
- Explainability: There is a growing need for CNNs to be more interpretable and explainable, especially in applications such as healthcare and finance. Future research will focus on developing techniques to better understand the inner workings of CNNs and to make their predictions more transparent.
- Robustness: Improving the robustness of CNNs will be a key focus of future research. This will involve developing techniques to make CNNs more resilient to variations in the input data, such as changes in lighting, viewpoint, or noise.
- Self-Supervised Learning: Self-supervised learning is a technique where a CNN learns to extract features from unlabeled data. This can be especially useful in scenarios where labeled data is scarce or expensive to obtain. Future research will focus on developing more effective self-supervised learning algorithms.
- Few-Shot Learning: Few-shot learning is a technique where a CNN is trained to learn new tasks with very little labeled data. This can be useful in scenarios where labeled data is difficult to obtain or where new tasks arise frequently. Future research will focus on developing more effective few-shot learning algorithms.
- Reinforcement Learning: Reinforcement learning is a technique where a CNN learns to take actions to maximize a reward signal. This can be useful in scenarios such as robotics and autonomous vehicles. Future research will focus on developing more effective reinforcement learning algorithms.
- Multi-Modal Learning: Multi-modal learning involves combining information from different modalities, such as text, images, and audio. This can be useful in applications such as natural language processing and video analysis. Future research will focus on developing more effective techniques for multi-modal learning.
- Energy Efficiency: Improving the energy efficiency of CNNs will be an important focus of future research, especially as more devices become connected to the internet of things (IoT). This will involve developing more efficient hardware and software architectures for CNNs.
In summary, there are many promising future directions for CNNs, including explainability, robustness, self-supervised learning, few-shot learning, reinforcement learning, multi-modal learning, and energy efficiency. Addressing these challenges will require ongoing research and development in the field of deep learning.
Further Readings
If you are interested in learning more about convolutional neural networks (CNNs), here are some suggested resources:
- “Deep Learning” by Ian Goodfellow, Yoshua Bengio, and Aaron Courville: This comprehensive textbook covers the fundamentals of deep learning, including CNNs. It is a great resource for anyone looking to dive deeper into the theory and practice of CNNs.
- “Convolutional Neural Networks (CNNs) – An Illustrated Explanation” by the Towards Data Science blog: This article provides a beginner-friendly introduction to CNNs, with plenty of visual aids to help explain the concepts.
- “A Comprehensive Guide to Convolutional Neural Networks” by the Analytics Vidhya blog: This article provides a detailed overview of CNNs, including their basic structure, layers, and applications.
- “Stanford CS231n: Convolutional Neural Networks for Visual Recognition” by Stanford University: This free online course covers the theory and practice of CNNs, with a focus on image classification and object detection.
- “Top 10 Deep Learning Frameworks for Developing Neural Networks” by the Analytics Insight blog: This article provides an overview of popular deep learning frameworks, including TensorFlow, PyTorch, and Keras, which can be used to implement CNNs.
- “Advances in Convolutional Neural Networks” by the Google AI blog: This article discusses recent advancements in CNNs, including transfer learning, attention mechanisms, and efficient architectures.
- “Applications of Convolutional Neural Networks” by the OpenAI blog: This article provides an overview of the many applications of CNNs, including image classification, object detection, and medical imaging.
These resources can provide a solid foundation for understanding CNNs and their applications.